{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
ExUnit capture log và Erlang IO system
Bài viết giải thích cách IO system trong Erlang vận hành và một số ứng dụng của nó.

Photo by trilemedia on Pixabay
Tối chủ nhật tuần trước, tui đang coi đá banh thì mấy bạn sales trong công ty nhắn tin liên tục qua Slack.
Răng thông số bán quảng cáo mấy tiếng vừa rồi trống trơn rứa hè?
Quảng cáo là nguồn sống của công ty, nên dù trận banh đang gây cấn, tui vẫn lết đi mở máy kiểm tra.
Thông số của các backend service liên quan tới mảng quảng cáo không có gì bất thường. Chắc không liên can tới mình. Đang poker face thì một đồng nghiệp bên Web báo rằng service A bị chết.
“Service A … WTF! Sao nghe quen quen …” <i class=”emoji” title=”:cold_sweat:”><img class=”emoji” src=”https://twemoji.maxcdn.com/36x36/1f630.png” /></i>
Ký ức cũ bỗng tràn về như thác đổ. Vài năm trước lúc mới vào công ty, một anh bạn bên team Web có nhờ tui viết cái tool để track game mới viết. Service vô cùng đơn giản: cái game sẽ gửi tracking events lên service, service gom events lại upload lên S3, từ đó bọn data scientist xử tiếp. Ngày ấy còn trẻ, ham vui, lại đang hype Elixir, nên tui đã nhận lời. Chứ thật ra xài Google Analytics cho rồi.
Kiến trúc của app rất tối giản. Một API endpoint duy nhất nhận event, đẩy vào ETS (built-in in-memory database của Erlang). Sau đó có một process định kì dump toàn bộ data trong ETS ra, rồi up lên S3. Toàn bộ service viết chừng 2 tiếng là xong.
Thôi rồi, <i class=”emoji” title=”:hankey:”><img class=”emoji” src=”https://twemoji.maxcdn.com/36x36/1f4a9.png” /></i> của mình thì mình phải hốt thôi.
Khi xác nhận service thật sự đã chết, tui vào đọc log và chẩn đoán nhanh:
[warn] Ranch acceptor reducing accept rate: out of file descriptors
[warn] Ranch acceptor reducing accept rate: out of file descriptors
[warn] Ranch acceptor reducing accept rate: out of file descriptors
eheap_alloc: Cannot allocate 1581921408 bytes of memory (of type "old_heap").Có 2 thứ tui rút ra nhanh ở đây là:
Service bị quá tải:
Ranch acceptor là một thư viện của Cowboy (webserver thông dụng trong Erlang) đóng vai trò xử lý các kết nối TCP đầu vào. Khi server quá tải (out of FDs), Ranch sẽ hãm tốc độ accept socket mới để giảm bớt tải cho Cowboy.
Không đủ memory:
Máy ảo Erlang thất bại trong việc cấp phát 1.47 GB. VM không có hạn mức về bộ nhớ, chính xác là nó không quan tâm, cấp phát không thành công thì nó crash.
Config lại ulimit hoặc tăng instance size là giải pháp được tính đến nhưng ta không nên làm điều đó mù quáng trước khi biết nút thắt (bottleneck) nằm ở đâu.
Giải pháp dễ làm nhất là restart service. A lê hấp, restart xong chạy thật! Cuộc sống của các bạn sale màu hồng trở lại; còn tui quay lại coi đá banh tiếp. Cơ mà thua cha nó luôn rồi. <i class=”emoji” title=”:angry:”><img class=”emoji” src=”https://twemoji.maxcdn.com/36x36/1f620.png” /></i>
Để trả lời cho câu hỏi chuyện gì đã xảy ra, ta phải dựa vào các telemetry metrics (thông số) thu thập được: host, Erlang VM, Web API…
Về metrics setup, tụi tui dùng TIGK stack (giống TICK stack cơ mà thay thế Chronograf bằng Grafana), và dùng Fluxter để xuất telemetry events của Elixir apps xuống Telegraf. Chi tiết các bạn có thể xem qua bài viết này.
Thông số host có thể lấy qua plug-in của Telegraf: CPU, memory, disk, network in/out.
Thông số máy ảo có thể trích xuất bằng các hàm của :erlang.statistics. Để tiết kiệm thời gian, tui dùng package vmstats. Một số thông số đáng quan tâm là:
Thông số của Web API thì chủ yếu ta cần throughput và latency, ta có thể lấy thông qua Plug.Telemetry.
Sau khi có đầy đủ thông số, ta có thể bắt đầu chẩn đoán. Vì nghi ngờ hệ thống bị overload, tui đã kiểm tra throughput và latency trước.

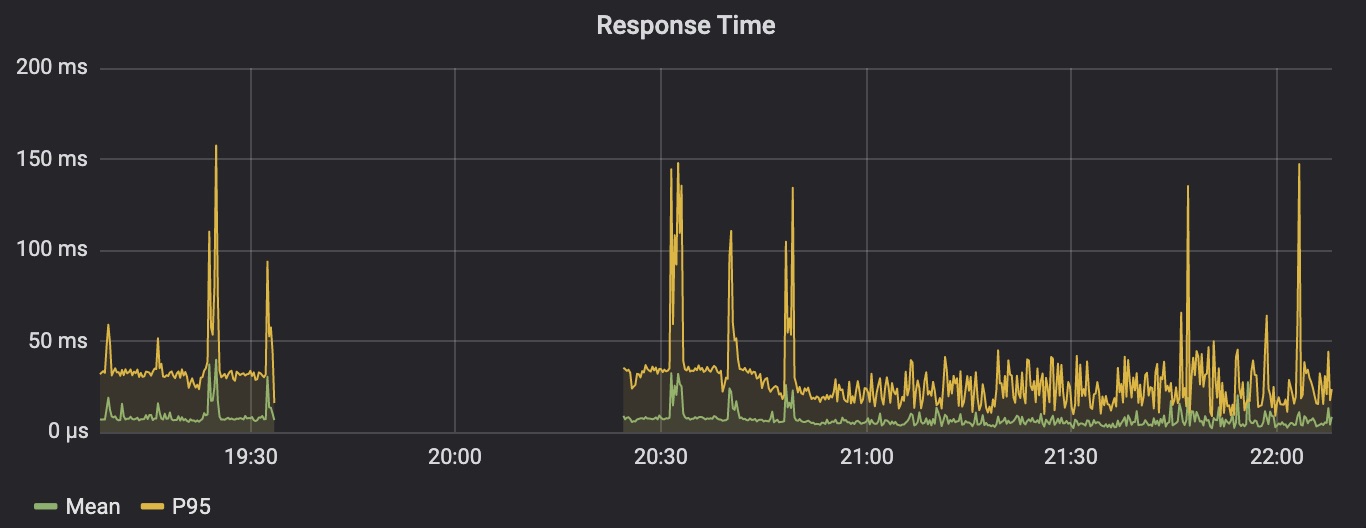
3K RPS <i class=”emoji” title=”:scream:”><img class=”emoji” src=”https://twemoji.maxcdn.com/36x36/1f631.png” /></i> ! Service giỡn chơi mà sao nhiều traffic quá vậy. Té ra sau cái game đó, bên team Web đã “chuẩn hóa” thư viện tracking của họ với service A làm trung tâm. Với xu hướng gia tăng của quảng cáo qua Web, lượng truy cập cũng nhân lên theo.
Tuy vậy độ trễ (latency, response time) vẫn làm tui băn khoăn. Khối lượng công việc của service, theo như mô tả là, rất đơn giản, nhưng độ trễ lại khá cao: 95th percentile có lúc lên tới 150ms. Bỏ data vào memory không thể có độ trễ cao như vậy được. Ta cần xem thêm các thông số khác.
Khi monitor một hệ thống Erlang, hai thông số rất quan trọng để nhận biết hệ thống có bị quá tải hay không: run queue và messages queued. Run queue là số lượng process ở trạng thái “runnable”, nôm na là số lượng task của các scheduler, còn messages queued là số lượng message trong các mailbox mà chưa được xử lý.
Để hiểu rõ thêm về process và mailbox trong Erlang, bạn có thể xem thêm tại bài viết Elixir/Erlang, Actors model và Concurrency.
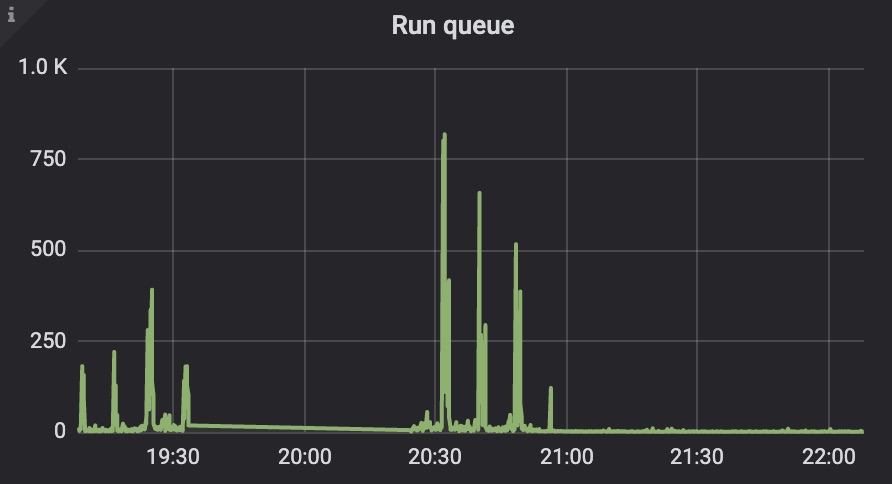
Trước khi tìm hiểu run queue ta cần lướt qua chút về Erlang scheduler.
Một ứng dụng Elixir tập hợp các Erlang process (actor) chạy trong cùng một máy ảo Erlang, định thời bởi Erlang scheduler. Một process ở khi ở trạng thái runnable (ví dụ nhận được message, được “đánh thức”, vv) sẽ được đưa vào run queue của scheduler. Scheduler sẽ chọn trong run queue của nó process tiếp theo để chạy.
Một máy ảo Erlang có thể có nhiều scheduler, thường tương ứng với số lượng CPU cores mà bạn có.
Khi một process được chọn để thực thi, nó chỉ được cấp một khoảng thời gian nhất định. Nếu quá thời hạn sẽ bị scheduler interrupt để nhường quyền thực thi cho task tiếp theo. Trong Erlang, không có cách nào để một process chiếm dụng scheduler mà không nhả ra (một số ngoại lệ với dirty scheduler và NIF).
Chiến lược định thời như vậy được gọi là preemptive scheduling, khác với cooperative scheduling cho phép task tự quyết định có nhả quyền thực thi hay không.
Tưởng tượng bạn cần cho một đám con nít ăn no và bạn chỉ có 1 cái muỗng. Sức ăn của đứa này khác đứa kia. Nếu bạn đưa cái muỗng cho tụi nó ăn lần lượt, đứa này ăn no xong tới đứa kia, rất có thể đứa cuối cùng sẽ đói meo râu: do những đứa ở trước và ăn nhiều sẽ ăn rất lâu. Nhưng nếu bạn đưa muỗng luân phiên, mỗi lần 1 muỗng, dần dần tụi nó cũng sẽ no hết. Về bản chất, tổng số lượng thời gian để đút hết đám đó của 2 cách là tương đương. Tuy nhiên, trải nghiệm của đám con nít đó có thể sẽ rất khác.
Preemptive scheduling là một trong nhiều lý do vì Erlang được dùng để xây dựng soft realtime system. Một hệ thống Erlang khi bị overload có thể sẽ khác với hệ thống dùng cooperative scheduling: latency ổn định hơn và performance xuống cấp mượt mà hơn.
Đương nhiên, đời không cho không ai cái gì cả, preemptive scheduling đi kèm với cost: scheduler phải tốn thêm chi phí để quản trị run queue. Run queue quá dài sẽ làm resource thực sự chạy code ít đi. Nói nôm na thì đút cơm cho 100 đứa sẽ mệt hơn đút cho 1-2 đứa.
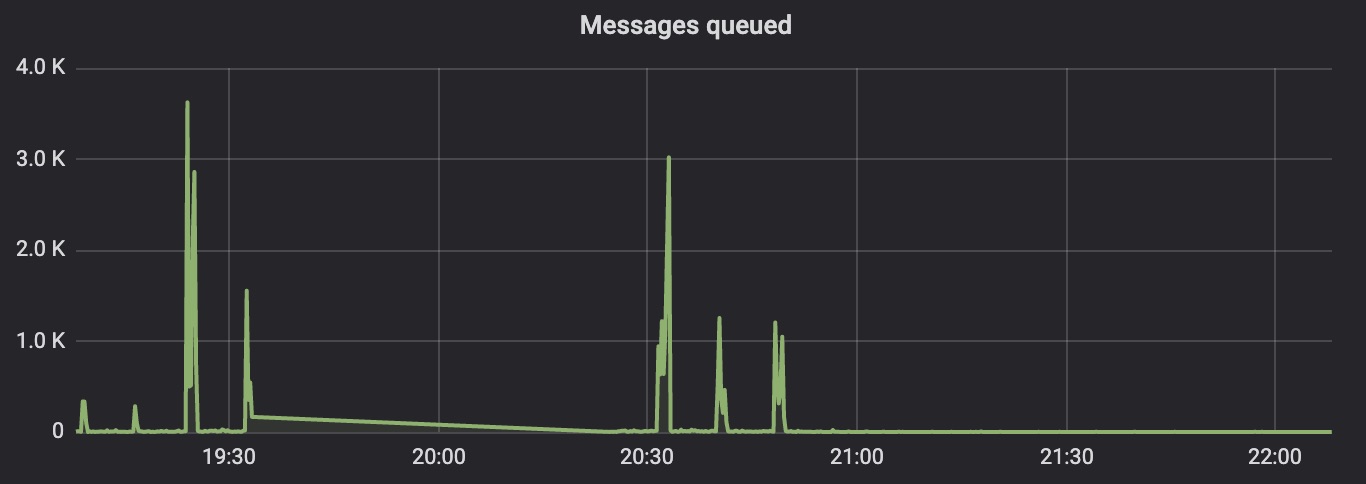
Các process Elixir/Erlang trao đổi thông tin với nhau bằng cách gửi message vào “mailbox” của nhau.
Để gửi message, sender process sẽ thử cấp phát trực tiếp một vùng nhớ trong heap của receiver process. Nếu không thành công (lock đã bị chiếm), nó sẽ cấp phát một heap fragment mới, copy message vào đó và insert pointer của vùng nhớ đó vào trong mailbox của receiver. Điều này giúp Erlang giảm thiểu lock contention tới mức tối đa. Đồng thời, ở một mức độ nào đó, kỹ thuật này giúp tạo back-pressure lên sender: bạn gởi message càng nặng thì chi phí của bạn càng cao, tốc độ gửi của bạn càng chậm.
Khi một process có càng nhiều message trong mailbox thì độ phân mảnh của heap lại càng cao. Điều này làm giảm performance của hệ thống và đồng thời cũng gây khó cho garbage collector mà tui sẽ nói ở phần tiếp theo.
Bộ dọn rác của Erlang là một per process generational semi-space copying collector (Cheney’s style). “Per process” là bởi vì mỗi process có stack và heap riêng, quá trình dọn rác chỉ diễn ra nội trong một process mà không ảnh hưởng đến những process đang thực thi trong những scheduler khác.
GC khi chạy sẽ dò root-set trong stack để copy data (terms) còn được reference trong heap từ space cũ sang space mới. Sau đó, space cũ sẽ được xóa đi.
eheap_alloc: Cannot allocate 1581921408 bytes of memory (of type "old_heap").Với những thông tin ở trên, ta có thể giải thích lý do vì sao app crash: khi chạy full sweep, GC cần copy “old” heap sang một space mới, nhưng không thể cấp phát nổi 1.47 GB.
Tuy nhiên ta cần phải tìm ra thủ phạm nào giữ tới 1.47 GB trong heap. Vì GC chạy cho từng process, ta sẽ xem xét 2 “loại” process mà ta có trong ứng dụng:
Ta có thể loại trừ các Web process bởi vì chúng sẽ chết sau khi request kết thúc. Lúc đó bộ nhớ của chúng được thu hồi ngay lập tức.
Nghi vấn rất cao được đặt cho một long-lived process nào đó trong hệ thống bị memory leak.
Với giả thiết đặt ra, tui bắt đầu khoanh vòng nghi vấn cho 3 long-lived process trong hệ thống:
Khả năng Fluxter là bottleneck là khá thấp vì thư viện này đã được tụi tui benchmark và optimize rất kĩ. Nhiều thủ thuật được áp dụng để giảm chi phí cho việc tính toán. Bởi vậy tui không đi sâu vào Fluxter.
defmodule Storage do
use GenServer
### APIs.
@doc """
Sync call tới chính nó để lấy ETS table.
"""
def checkout() do
GenServer.call(Storage, :checkout)
end
@doc """
Bỏ event vào trong ETS.
"""
def put(event) do
:ets.insert(checkout(), {"events", event})
end
@doc """
Lấy và xóa hết events trong ETS.
"""
def pop_all() do
data = Enum.map(:ets.lookup(checkout(), "events"), fn {_, event} -> event end)
:ets.delete(checkout(), "events")
data
end
### GenServer calbacks.
def init(_) do
table = :ets.new(__MODULE__, [:duplicate_bag, :public, read_concurrency: true])
{:ok, table}
end
def handle_call(:checkout, _from, table) do
{:reply, table, table}
end
endCó một lỗi mà rất nhiều lập trình viên Elixir/Erlang hay mắc phải khi dùng ETS. Trong process, dù cho message được gửi thế nào (cast/call/info), mọi message sẽ được xử lý lần lượt.
Mỗi lần put hay pop_all được gọi, nó phải checkout ETS table với throughput là 3000 ops/sec. Điều này làm cho số lượng message trong Storage lên cao và trở thành bottleneck của chính nó, làm latency lên cao.
Cách sửa khá đơn giản: ta đặt tên cho ETS table.
def init(_) do
# Lấy tên module hiện tại đặt cho ETS.
:ets.new(__MODULE__, [:named_table, :duplicate_bag, :public, read_concurrency: true])
{:ok, nil}
end
def put(event) do
# Insert thẳng mà không cần phải checkout làm gì.
:ets.insert(__MODULE__, {"events", event})
endNhư thế ta đã giải quyết được vấn đề latency và đảm bảo API sẽ chạy nhanh nhất có thể. Độ trễ giảm, request xong nhanh, nhờ đó run queue cũng giảm theo và ứng dụng được tăng tốc.
Quay lại vấn đề memory leak, mặc dù Storage có vấn đề về hiệu năng cơ mà tỉ lệ nó làm leak memory là rất thấp.
Code của Storage có thể tóm tắt đơn giản thành 3 bước:
every 7 minutes do
1. Call Storage.pop_all()
2. Encode to JSON
3. PUT to S3
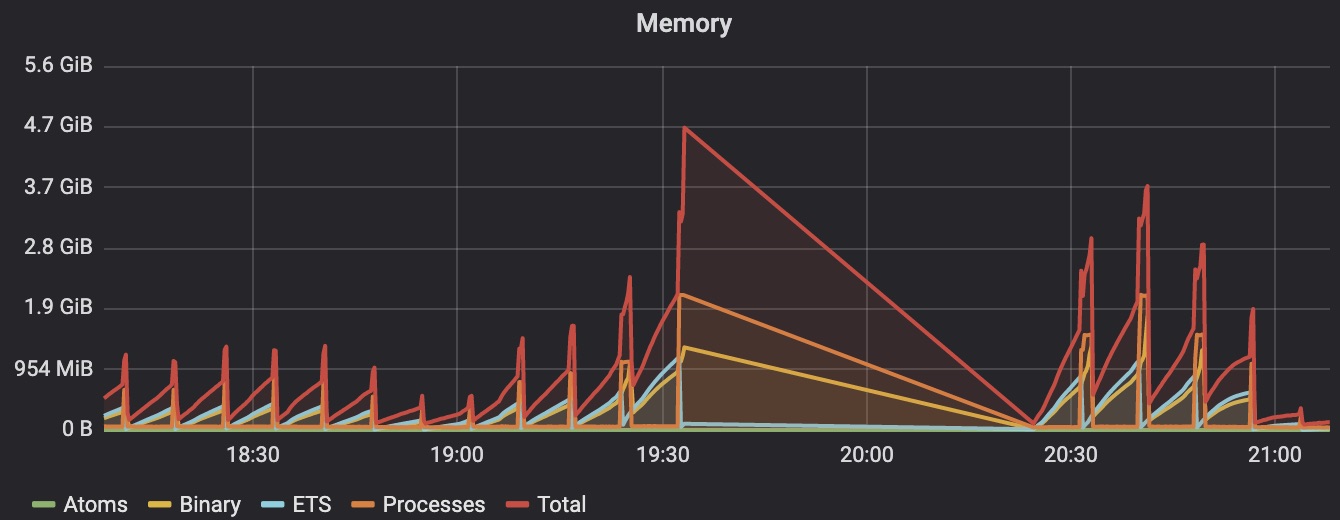
Kết hợp với biểu đồ thông số bộ nhớ, tui mơ hồ mường tượng được memory leak có thể đã xảy ra như thế nào:
Vấn đề nằm ở việc Uploader đợi quá lâu giữa mỗi lần upload, làm tích tụ event. Sau khi sửa thành 60 giây, mọi thứ đã khả quan hơn.
Trước hết là Elixir quá tuyệt vời <i class=”emoji” title=”:sweat:”><img class=”emoji” src=”https://twemoji.maxcdn.com/36x36/1f613.png” /></i>. Nghe có vẻ vô lý, cơ mà một service ất ơ, của một newbie, viết trong vòng 2 tiếng đồng hồ vẫn có khả năng xử lý được một lượng load cao với latency không quá tệ, chỉ chết vì memory leak, bạn còn đòi hỏi được gì hơn nữa. Chưa kể, cái máy (m5.large) chỉ tốn có $69 để chạy thôi.
Tui mong đã chia sẻ được cùng các bạn cách monitor một chương trình Elixir/Erlang. Hy vọng cũng sẽ hữu ích cho cả các bạn không lập trình Elixir nhưng vận hành máy ảo Erlang như hệ thống RabbitMQ hay Riak:
Bài viết giải thích cách IO system trong Erlang vận hành và một số ứng dụng của nó.
Bài viết giới thiệu về IO data, Vectored I/O và tối ưu hóa hệ thống dùng Elixir bằng cách tận dụng Vectored I/O.